What is a Kubernetes headless service, what does it do/accomplish, and what are some legitimate use cases for it?
A Kubernetes headless service is a service that does not have a dedicated load balancer. This service is typically used for stateful applications, such as databases, where it is essential to maintain a consistent network identity for each instance. If a client needs to connect with all of the pods, this cannot be done with a regular Kubernetes service where the ClusterIP is configured. The service will not be able to forward each connection to a randomly selected pod.
How does Regular Service Object Works?
Let's look at the regular Kubernetes service where the ClusterIP is configured. Apply the following yaml configuration.
cat <<EOF | kubectl apply -f -
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: normal-nginx
labels:
app: normal-nginx # Deployment labels to match with replicaset labels and pods labels
spec:
replicas: 3
selector:
matchLabels:
app: normal-nginx # Replicaset to manage pods with labels
template:
metadata:
labels:
app: normal-nginx # Pods labels
spec:
containers:
- name: nginx
image: nginx
---
apiVersion: v1 # v1 is the default API version. It is the latest version of the Core API.
kind: Service # Service is a collection of Pods that are running on a host.
metadata:
name: normal-nginx # name of the service
labels:
app: normal-nginx # label for the service
spec:
selector:
app: normal-nginx # label for the service
ports:
- port: 80 # port to expose
targetPort: 80 # container port
protocol: TCP # protocol to use for the port mapping ( example TCP, UDP, or SCTP)
type: ClusterIP # type of service to create, ClusterIP is the default. Others are NodePort, LoadBalancer, and ExternalName.
EOF
Output:
deployment.apps/normal-nginx created
service/normal-nginx created
Let's validate, get service first
kubectl get svc -o wide | grep normal-nginx
Output:
normal-nginx ClusterIP 10.96.141.251 <none> 80/TCP 48s app=normal-nginx
and list of normal-nginx pods
oc get pods -o wide | grep normal-nginx
Output:
normal-nginx-d98bff4-jk65q 1/1 Running 0 74s 10.244.2.20 kind-worker2 <none> <none>
normal-nginx-d98bff4-sbzf9 1/1 Running 0 74s 10.244.1.19 kind-worker <none> <none>
normal-nginx-d98bff4-wbj7q 1/1 Running 0 74s 10.244.2.19 kind-worker2 <none> <none>
Now if you run nslookup to normal-nginx service object you will see following output:
kubectl run -it --rm debug --image=tutum/dnsutils --restart=Never nslookup normal-nginx
Output:
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: normal-nginx.default.svc.cluster.local
Address: 10.96.141.251
pod "debug" deleted
Where nslookup normal-nginx is equal to ClusterIP address.
How does Headless Service Object Works?
For a client to connect to all pods, it needs to know the IP addresses of each pod. One option is for the client to call the Kubernetes API server and get a list of pods and IP addresses through an API call. However, using the API server is not ideal because you should always strive to minimize API calls to improve performance. The other option is to use a headless service which will give you a static list of IP addresses that you can use to connect to the pods.
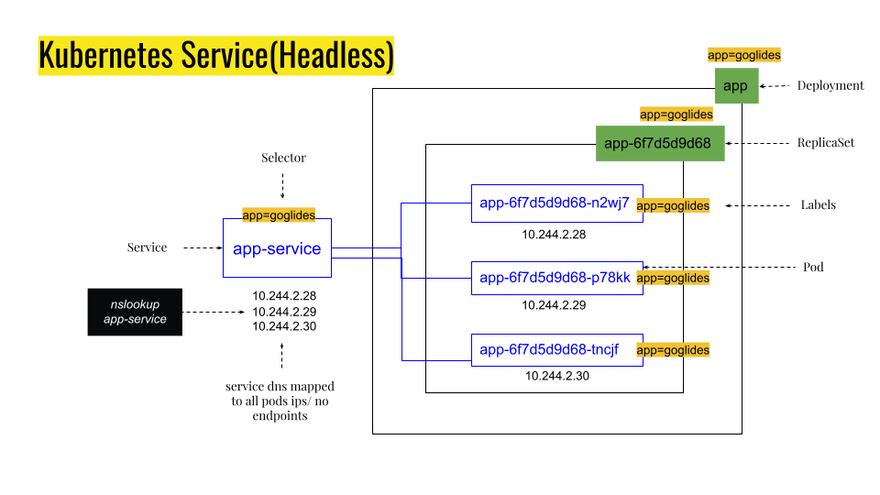
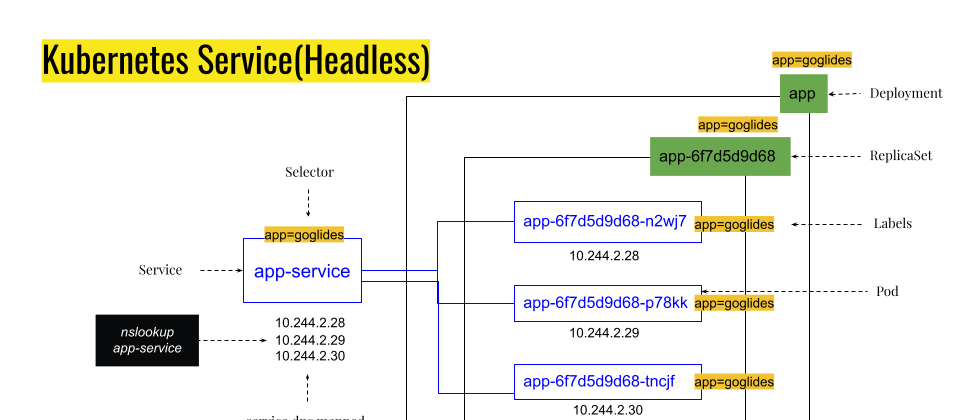
Kubernetes allows clients to find the IP addresses of the pods in a service. Usually, when you look up the service address, you get a single IP address: the address of a Load balancer or ClusterIP. If your service is headless, then Kubernetes will give you a list of all IP addresses for the pods that are part of the service. Clients can look up the IPs for all the pods that are part of the service by doing a DNS A record lookup. The client can then use that information to connect to one, many, or all of the pods.
A headless service is also helpful when performing health checks on individual pods. With regular service, the health check is performed on the load balancer, which just forwards traffic to the pods. This means a pod could be unhealthy, but the load balancer would never know because it just forwards traffic. With a headless service, the health check is performed on the individual pod, so you can be sure that the traffic is routed to a healthy pod.
Let's run the same test for headless service. First, create deployment objects and headless services. Setting the clusterIP field in a service spec to None means that Kubernetes will not assign the service a cluster IP address, which you can do as follows,
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: headless-nginx
labels:
app: headless-nginx # Deployment labels to match with replicaset labels and pods labels
spec:
replicas: 3
selector:
matchLabels:
app: headless-nginx # Replicaset to manage pods with labels
template:
metadata:
labels:
app: headless-nginx # Pods labels
spec:
containers:
- name: nginx
image: nginx
---
apiVersion: v1 # v1 is the default API version. It is the latest version of the Core API.
kind: Service # Service is a collection of Pods that are running on a host.
metadata:
name: headless-nginx # name of the service
labels:
app: headless-nginx # label for the service
spec:
selector:
app: headless-nginx # label for the service
clusterIP: None # this is will point directly to pods, nslookup will rerun pod ips
ports:
- port: 80 # port to expose
targetPort: 80 # container port
protocol: TCP # protocol to use for the port mapping ( example TCP, UDP, or SCTP)
type: ClusterIP # type of service to create, ClusterIP is the default. Others are NodePort, LoadBalancer, and ExternalName.
EOF
You will see output something like this,
deployment.apps/headless-nginx created
service/headless-nginx created
Let's validate,
kubectl get svc -o wide
Output:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
headless-nginx ClusterIP None <none> 80/TCP 43s app=headless-nginx
kubectl get pods -o wide
Output:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
headless-nginx-5795b5d5db-9sv8k 1/1 Running 0 71s 10.244.2.18 kind-worker2 <none> <none>
headless-nginx-5795b5d5db-d5xmn 1/1 Running 0 71s 10.244.1.18 kind-worker <none> <none>
headless-nginx-5795b5d5db-dgwzq 1/1 Running 0 71s 10.244.1.17 kind-worker <none> <none>
Now run nslookup test as follows,
kubectl run -it --rm debug --image=tutum/dnsutils --restart=Never nslookup headless-nginx
Output:
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: headless-nginx.default.svc.cluster.local
Address: 10.244.1.18
Name: headless-nginx.default.svc.cluster.local
Address: 10.244.1.17
Name: headless-nginx.default.svc.cluster.local
Address: 10.244.2.18
pod "debug" deleted
As you can see, nslookup command returned three IP addresses for headless service.
Some of the use cases of headless service
Database replication and clustering: Data is synchronized between two or more databases in database replication. Services like MongoDB, Couchbase, etc., use headless services to cluster and synchronize data between databases.
Create Stateful service: StatefulSet is the workload API object used to manage stateful applications. It manages the deployment and scaling of a set of Pods and provides guarantees about the ordering and uniqueness of these Pods. Headless services expose a StatefulSet's Pods with stable hostnames and IP addresses. RabbitMQ or Kafka (or any other message broker service) can be deployed to Kubernetes using a stateful set.
Container Orchestration: It is not recommended to expose container orchestration tools like a marathon, kube-scheduler, etc., directly to the internet, but headless services can help you expose these tools internally and keep them secure from the outside world.
TLS termination – Using headless services, we can terminate TLS at any node, and after that, the communication can happen over an unencrypted connection.
Service Discovery – As we saw in the example, headless services can be used to execute
nslookupcommands and get IP addresses of Pods.
Drawbacks of headless service.
There are some drawbacks to using a headless service. The main one is that it can be more difficult to debug because you have to look at the individual pods instead of a single load balancer. This is usually not a big deal because most services have some sort of logging that can help you debug problems.
Conclusion:
- A headless service does not have a clusterIP assigned to non-headless services.
- It has only endpoints, i.e., hostnames and IP addresses of the Pod.
- There is no load balancing between Pods as with other services.
- Inter-pod communication can be done using Pod’s hostnames and IP addresses.
- Headless services are mainly used for clusters of applications like MongoDB, Kafka, Cassandra, etc.
- Endpoints are used to point the service to a set of Pods. They can be DNS names or IP addresses.
- Headless services can be used for service discovery.
Please comment if you have any queries or suggestions on improving this blog.
Thank you for reading!


Top comments (0)