Both NVIDIA Hopper and Ampere represent cutting-edge GPU architectures pushing the boundaries of AI and HPC performance. Choosing the right one depends on your specific needs and budget. Let's dive into their similarities and differences to help you make an informed decision:
Source: Nvidia Official Website
Similarities:
- Tensor Cores: Both architectures boast powerful Tensor Cores designed to accelerate AI workloads, significantly speeding up training and inference for deep learning models.
- High-bandwidth memory: Both utilize high-bandwidth memory like GDDR6 or HBM2, ensuring efficient data transfer for demanding computational tasks.
- Scalability: Both offer scalability through multi-GPU configurations for tackling massive datasets and complex problems.
- Advanced software support: Both benefit from NVIDIA's robust software ecosystem, including CUDA, cuDNN, and TensorRT, for optimizing diverse workloads.
Differences:
Performance:
Double-precision FP64:
- DPX instructions: Hopper introduces new instructions called DPX specifically optimized for double-precision (FP64) arithmetic. These instructions improve the efficiency of calculations involving large numbers by reducing memory access and data movement. This translates to a 7x performance boost compared to Ampere for FP64 workloads, making Hopper ideal for scientific computing tasks like simulations and high-precision engineering calculations.
- Larger L2 cache: Hopper also comes with a significantly larger L2 cache compared to Ampere. This allows the GPU to store more data closer to the processing cores, reducing the need to fetch data from slower memory, further contributing to faster FP64 performance.
TF32/FP32:
- Increased tensor core throughput: Hopper boasts a tripling of floating-point operations per second (FLOPS) for FP32, FP16, and INT8 data types compared to Ampere. This is primarily achieved through improvements in the tensor cores, specialized hardware units designed for accelerating matrix operations common in AI and HPC tasks. These advancements lead to significant speedups in various applications, including:
- AI training and inference: Faster processing of training data and improved performance for running trained models.
- High-performance computing (HPC): Increased speed for simulations and other computationally intensive tasks involving large datasets.
- Graphics and video processing: Enhanced performance for real-time rendering and video editing.
Transformer Engine:
-
Dedicated hardware for NLP: Hopper features a dedicated Transformer Engine specifically designed to accelerate natural language processing (NLP) workloads. This engine is optimized for the computations involved in Transformer models, which are widely used in tasks like machine translation, text summarization, and chatbots. The Transformer Engine offers an advantage over Ampere for these specific NLP tasks by:
- Reducing memory bandwidth requirements: The engine efficiently handles the large amounts of data processed by Transformer models, leading to lower memory traffic and improved performance.
- Providing specialized instructions: The engine includes instructions tailored for the specific operations used in Transformer models, further enhancing processing efficiency.
Overall, the performance improvements in Hopper compared to Ampere represent a significant leap forward in GPU capabilities. These advancements cater to a wider range of applications, making Hopper a compelling choice for demanding AI, HPC, and scientific computing workloads.
Features:
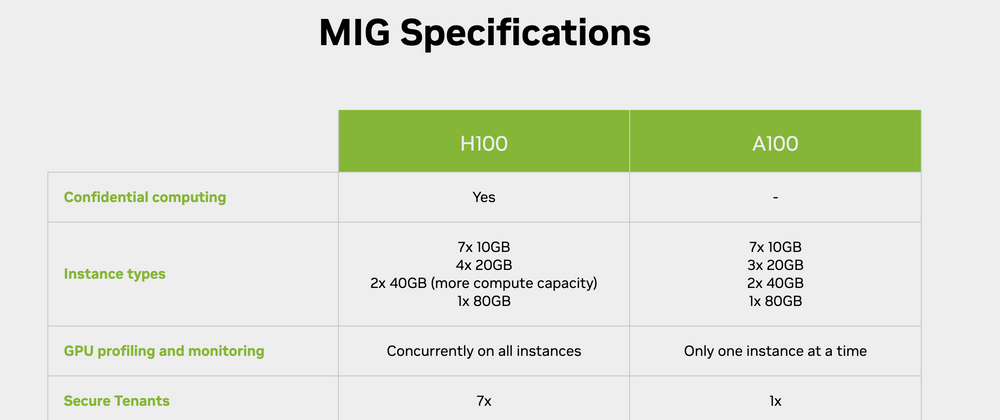
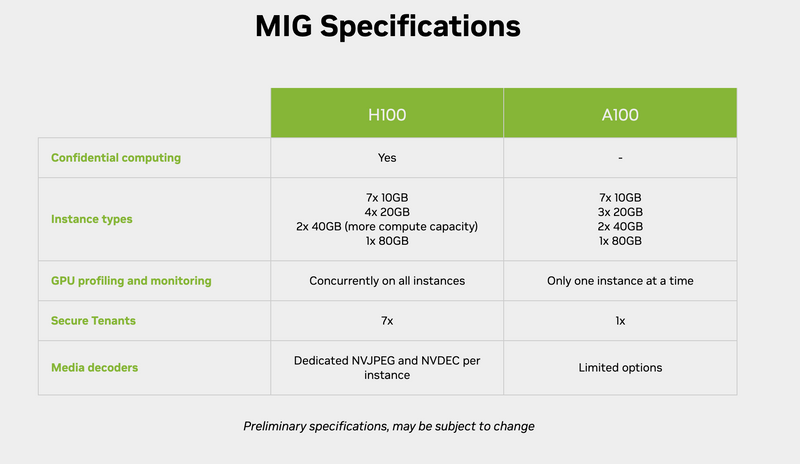
- Multi-Instance GPU (MIG): Both support MIG, but Hopper introduces new MIG capabilities like LLM Engine and PCIe Gen 5, enabling finer-grained resource allocation and improved bandwidth for demanding parallel workloads.
- Storage Options: Hopper offers wider storage options with PCIe Gen 5 support and direct access to PCIe NVMe drives, potentially speeding up data access for storage-intensive applications.
Price & Availability:
- Cost: Hopper represents the latest and most advanced technology, making it likely to be more expensive than Ampere GPUs.
- Availability: Hopper is currently in early stages of deployment, while Ampere GPUs are more widely available.
So, which is better?
It depends on your needs and priorities:
Choose Hopper if:
- Your workload heavily relies on double-precision computing or NLP tasks.
- You require maximum performance and cutting-edge features, regardless of cost.
- You can wait for wider availability and potentially higher initial investment.
Choose Ampere if:
- Your workload focuses on single-precision or mixed-precision AI tasks.
- Budget is a key concern, and cost-effectiveness is crucial.
- You need immediate availability and a well-established technology ecosystem.
Remember, both Hopper and Ampere are powerful architectures capable of tackling demanding AI and HPC workloads. Evaluating your specific needs, budget, and application requirements will guide you toward the optimal choice.


Top comments (1)
Very interesting architecture