we rely on a feature called replication to keep data in sync across all cluster nodes. With the replication feature enabled, all changes made on the primary node are propagated and applied to the rest of the cluster, so that the same data is stored on every node. When working with replication, there are certain trade-offs you have to be aware of. As there are several types of replication, we should first have a look at how replication works.
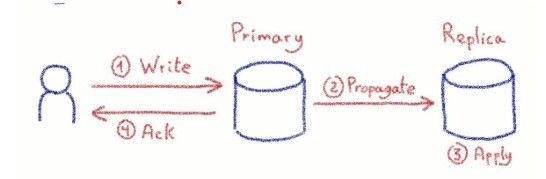
Asynchronous replication
The first one is called asynchronous replication. With this replication type, write queries are acknowledged as soon as the primary has executed them and stored the result on disk. The application can continue its work as soon as it receives this acknowledgment. In parallel, the changes are being propagated and applied to the rest of the cluster, which means that those changes won’t be visible on the replicas until they are fully propagated and applied. This also means that if you lose the primary before changes have been propagated, not-yet-propagated data will be lost.
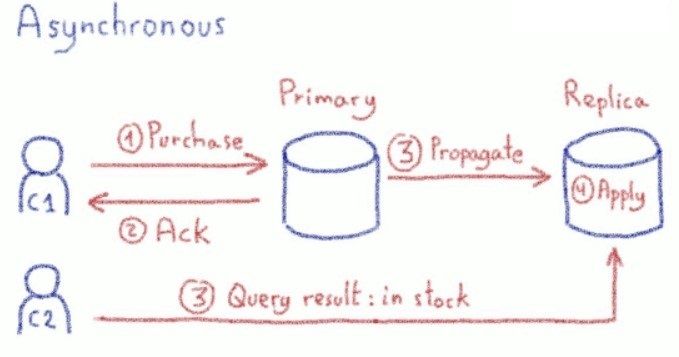
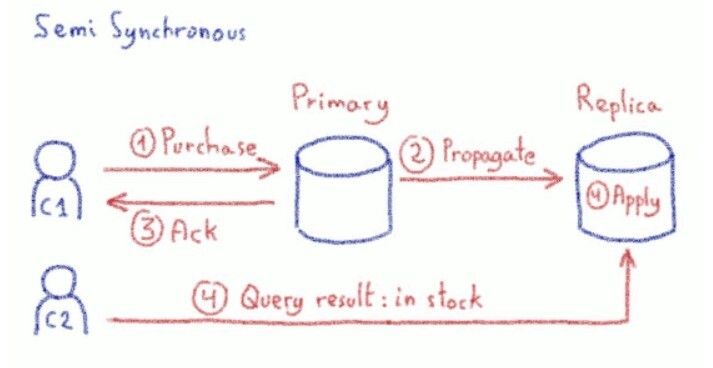
Semi Synchronous replication
The second one is called semi-synchronous replication. With this one, write queries are acknowledged as soon as the changes have been propagated to replicas. Propagated, but not necessarily applied: changes might not yet be visible on the replicas. But if the primary node is lost, replicas have all the data they need to apply the changes.
Synchronous replication
The last one is synchronous replication. The name is self-explanatory, but let us walk through how it works. In this mode, write queries are only acknowledged when changes have been propagated AND applied to the replicas. Obviously, this is the most secure way to replicate data: no data or progress is lost if there is a primary node failure.
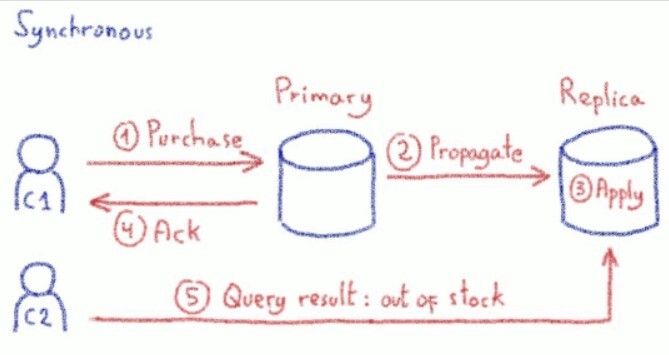
A real world example
But a real example is worth a thousand technical explanations: Imagine you are running a website selling hand-made items. You have two customers and an item with a single piece remaining. Now imagine that the first customer is buying this last piece, and that the second customer checks availability at the exact same time that the first one is completing his purchase.
Buying an item is a write query as you need to update the stock, so you must perform it on the primary node. Displaying the webpage is a read query, so you decide to perform it on a replica node. What happens for the second customer if he/she displays the webpage at the same exact moment that the first customer receives the purchase confirmation? Does he see the item as in or out of stock.
As you will probably have guessed by now, it depends on the type of replication you have chosen for your database. With an asynchronous or semi-synchronous replication, the customer would see the item as still available. With a synchronous, she would see the item as out of stock.

This can be confusing: this is always the case. The real difference between the modes here is that in the synchronous mode, the first customer’s purchase will take longer to complete (not complete before all replicas have applied the change). The logical difference is not between the time it takes for the change to be applied, it’s between when the first client sees her purchase completed.
Before going all in for synchronous replication you must take into account a crucial point: the latency. Indeed, waiting for all replicas to receive and apply the changes takes time. Latency impacts your website or application reactivity, and thus potentially your revenue. Indeed, multiple studies show that having a higher latency on purchase operations directly translates to fewer complete purchases, which you probably don’t want.
You might now get where I’m going with this: asynchronous replication operations take less time to complete and thus make your applications more reactive, but enable undesirable consequences like items appearing in stock when they are not.


Top comments (3)
I recall that you talked about this during our CKA session. Nicely written. Do MySQL databases provide replication as well?
Yes sir,
You can easily Replicate your MySQL Database by implementing the following methods:
Method 1: Using Master-Slave Approach to Replicate MySQL Database
MySQL allows users to use the master-slave mechanism to replicate their data across numerous MySQL databases and thereby ensure high data availability at all times.
Method 2: Using Hevo Data to Replicate MySQL Database
Hevo Data, an Automated Data Pipeline, provides you with a hassle-free solution to perform the MySQL Replication with an easy-to-use no-code interface. Hevo is fully managed and completely automates the process of not only replicating data from MySQL but also enriching the data and transforming it into an analysis-ready form without having to write a single line of code.
I write a another blog to explain it.
Awesome I will wait for the blog.
I just googled it, looks like Hevo method (seems commercial) you can technically use for any data?
I also found another opensource tool ReplicaDB which seems pretty cool as well. I will give it a shot later.