Let's look at what HAProxy is and how it works before we start setting it.
What is HAProxy?
HAProxy (High Availability Proxy) is a free, fast, and reliable solution offering high availability, load balancing, and proxying for TCP and HTTP-based applications. It is written in C and has a reputation for being fast and efficient (in terms of processor and memory usage).
How does HAProxy work?
When an incoming request arrives, it will be received by the Load Balancer (HAProxy), which then forwards the request to one of the back-end servers. The Load Balancer uses a scheduling algorithm (like Round Robin) to determine which server should receive the request.
The back-end server processes the request and sends a response back to the Load Balancer. The Load Balancer then forwards the answer to the client.
The Load Balancer ensures that the client always receives a response. If one of the back-end servers goes down, the Load Balancer will stop sending requests to that server. Requests will be routed only to the working servers.
Setting up HAProxy for a Hyperconverged OCP Cluster
Now let's see how we can set up HAProxy for a Hyperconverged OCP Cluster. As we all know, HAProxy is a Load Balancer for routers in OCP; we can utilize HAProxy to load-balance API Server. But we shouldn't use the k8s managed HAproxy instance. If something happens to all instances of k8s API, it will be harder to recover instances of HAProxy. Instead, we'll utilize the second instance of HAProxy managed by the Kubelet as static pods.
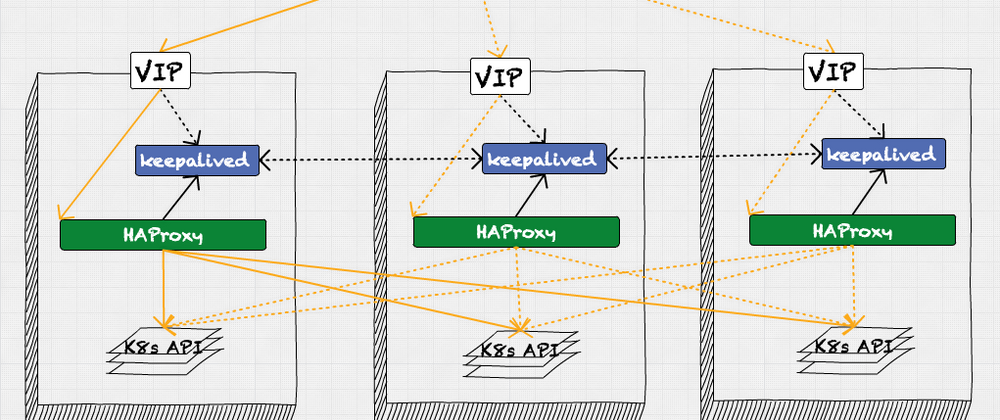
Keepalived - HAProxy workflow
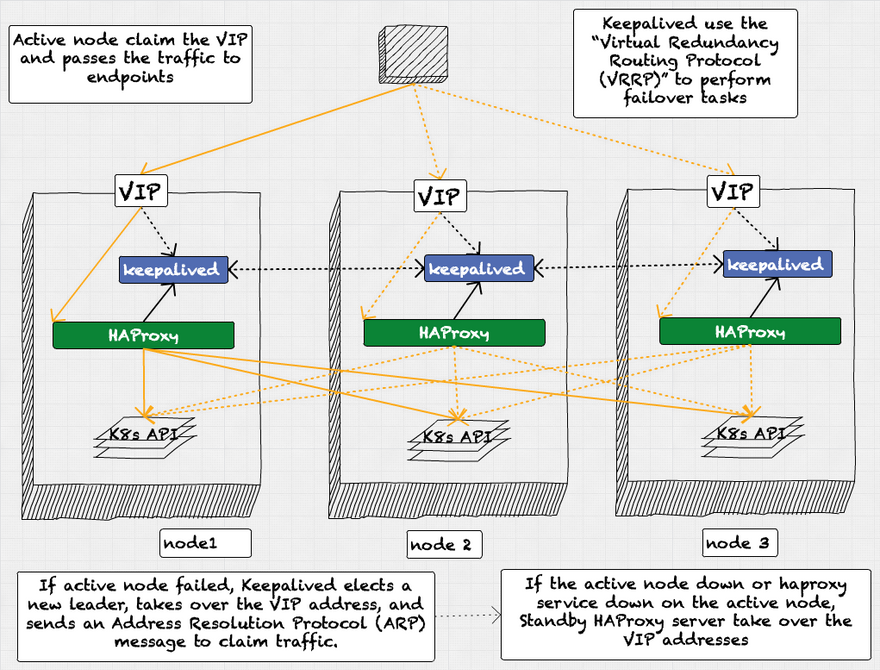
- For TCP load balancing, there are three HAProxies: one active and two standby, ready to take over if the active one fails.
- Keepalived use the “Virtual Redundancy Routing Protocol (VRRP)” to perform failover tasks. Active node claim the VIP and passes the traffic to endpoints.
- If active node failed, Keepalived elects a new leader, takes over the VIP address, and sends an Address Resolution Protocol (ARP) message to claim traffic.
- If the active node down or HAProxy service down on the active node, Standby HAProxy server take over the VIP addresses.
Take a look at static pods of HAProxy instance,
kind: Pod
apiVersion: v1
metadata:
name: haproxy
namespace: openshift-openstack-infra
creationTimestamp:
deletionGracePeriodSeconds: 65
labels:
app: openstack-infra-api-lb
spec:
volumes:
- name: resource-dir
hostPath:
path: "/etc/kubernetes/static-pod-resources/haproxy"
- name: kubeconfigvarlib
hostPath:
path: "/var/lib/kubelet"
- name: run-dir
empty-dir: {}
- name: conf-dir
hostPath:
path: "/etc/haproxy"
- name: chroot-host
hostPath:
path: "/"
containers:
- name: haproxy
securityContext:
privileged: true
image: quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:555efd05a7c11ebd96922a0541556781e093fb7be09aed2b3d6f7973982e1a88
env:
- name: OLD_HAPROXY_PS_FORCE_DEL_TIMEOUT
value: "120"
command:
- "/bin/bash"
- "-c"
- |
#/bin/bash
verify_old_haproxy_ps_being_deleted()
{
local prev_pids
prev_pids="$1"
sleep $OLD_HAPROXY_PS_FORCE_DEL_TIMEOUT
cur_pids=$(pidof haproxy)
for val in $prev_pids; do
if [[ $cur_pids =~ (^|[[:space:]])"$val"($|[[:space:]]) ]] ; then
kill $val
fi
done
}
reload_haproxy()
{
old_pids=$(pidof haproxy)
if [ -n "$old_pids" ]; then
/usr/sbin/haproxy -W -db -f /etc/haproxy/haproxy.cfg -p /var/lib/haproxy/run/haproxy.pid -x /var/lib/haproxy/run/haproxy.sock -sf $old_pids &
#There seems to be some cases where HAProxy doesn't drain properly.
#To handle that case, SIGTERM signal being sent to old HAProxy processes which haven't terminated.
verify_old_haproxy_ps_being_deleted "$old_pids" &
else
/usr/sbin/haproxy -W -db -f /etc/haproxy/haproxy.cfg -p /var/lib/haproxy/run/haproxy.pid &
fi
}
msg_handler()
{
while read -r line; do
echo "The client send: $line" >&2
# currently only 'reload' msg is supported
if [ "$line" = reload ]; then
reload_haproxy
fi
done
}
set -ex
declare -r haproxy_sock="/var/run/haproxy/haproxy-master.sock"
declare -r haproxy_log_sock="/var/run/haproxy/haproxy-log.sock"
export -f msg_handler
export -f reload_haproxy
export -f verify_old_haproxy_ps_being_deleted
rm -f "$haproxy_sock" "$haproxy_log_sock"
socat UNIX-RECV:${haproxy_log_sock} STDOUT &
if [ -s "/etc/haproxy/haproxy.cfg" ]; then
/usr/sbin/haproxy -W -db -f /etc/haproxy/haproxy.cfg -p /var/lib/haproxy/run/haproxy.pid &
fi
socat UNIX-LISTEN:${haproxy_sock},fork system:'bash -c msg_handler'
resources:
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: conf-dir
mountPath: "/etc/haproxy"
- name: run-dir
mountPath: "/var/run/haproxy"
livenessProbe:
initialDelaySeconds: 50
httpGet:
path: /haproxy_ready
port: 50936
terminationMessagePolicy: FallbackToLogsOnError
imagePullPolicy: IfNotPresent
- name: haproxy-monitor
securityContext:
privileged: true
image: quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:c1f0f7c54f0f2ecd38fdf2667651f95153a589bd7fe4605f0f96a97899576a08
command:
- "/bin/bash"
- "-c"
- |
cp /host/etc/resolv.conf /etc/resolv.conf
monitor /var/lib/kubelet/kubeconfig /config/haproxy.cfg.tmpl /etc/haproxy/haproxy.cfg --api-vip 172.21.104.25
resources:
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: conf-dir
mountPath: "/etc/haproxy"
- name: run-dir
mountPath: "/var/run/haproxy"
- name: resource-dir
mountPath: "/config"
- name: chroot-host
mountPath: "/host"
- name: kubeconfigvarlib
mountPath: "/var/lib/kubelet"
livenessProbe:
initialDelaySeconds: 10
exec:
command:
- /bin/bash
- -c
- |
cmp /host/etc/resolv.conf /etc/resolv.conf
terminationMessagePolicy: FallbackToLogsOnError
imagePullPolicy: IfNotPresent
hostNetwork: true
tolerations:
- operator: Exists
priorityClassName: system-node-critical
status: {}
and the configuration for this HAProxy pods
defaults
maxconn 20000
mode tcp
log /var/run/haproxy/haproxy-log.sock local0
option dontlognull
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 86400s
timeout server 86400s
timeout tunnel 86400s
frontend main
bind :::{{ .LBConfig.LbPort }} v4v6
default_backend masters
listen health_check_http_url
bind :::50936 v4v6
mode http
monitor-uri /haproxy_ready
option dontlognull
listen stats
bind localhost:{{ .LBConfig.StatPort }}
mode http
stats enable
stats hide-version
stats uri /haproxy_stats
stats refresh 30s
stats auth Username:Password
backend masters
option httpchk GET /readyz HTTP/1.0
option log-health-checks
balance roundrobin
{{- range .LBConfig.Backends }}
server {{ .Host }} {{ .Address }}:{{ .Port }} weight 1 verify none check check-ssl inter 1s fall 2 rise 3
{{- end }}
The above settings must be applied to all three controller machines.


Top comments (0)